SayIT! – Czyli jak sprawić aby komputer przemówił
Zapewne wielu z Was zastanawiało się kiedyś, jak sprawić, aby komputer zaczął mówić. Być może chcielibyście, aby komunikaty w waszej aplikacji były oprócz wyświetlania także odczytywane? A co powiecie na głosowy czytnik kanałów RSS albo informację o otrzymanym nowym e-mailu? Pomysły można mnożyć, a Microsoft udostępnił nam do tych celów odpowiednie API.
Począwszy od wersji 3.0 platformy .NET, otrzymujemy zarządzaną wersję biblioteki mowy. Jest to wrapper do biblioteki Microsoft Speech Object Library (speechlib.dll).
Korzystanie z biblioteki rozpoczniemy od dodania do naszego projektu referencji do zestawu System.Speech. Syntezator mowy jest dostępny w przestrzeni nazw System.Speech.Synthesis, którą należy dodać w sekcji using. Cały syntezator, wszystkie jego właściwości, metody oraz zdarzenia zostały umieszczone w jednej klasie: SpeechSynthesizer.
Aby komputer się do nas odezwał, należy utworzyć obiekt syntezatora oraz wywołać jego metodę Speak z tekstowym parametrem. Najprostszy sposób:
var synth = new SpeechSynthesizer();
synth.Speak(string.Format("Hello! My name is {0}.", synth.Voice.Name));
Powyższy kod spowoduje, że komputer ładnie nam się przedstawi, podając nazwę domyślnego głosu zainstalowanego w systemie. Jeśli uruchamiamy program pod kontrolą systemu Windows XP to domyślnie usłyszymy głos Microsoft Sam, natomiast dla Windows Vista oraz Windows 7 będzie to Microsoft Anna.
Klasa SpeechSynthesizer udostępnia nam też kilka właściwości, m.in:
Rate – reguluje prędkość odtwarzania, przyjmuje wartości z zakresu -10 do 10 (odczyt i zapis)
Volume – ustawia głośność odtwarzania, przyjmuje wartości z zakresu 0 do 100 (odczyt i zapis)
Voice – obiekt typu VoiceInfo, który zawiera informacje o aktualnie wykorzystywanym głosie (tylko odczyt)
State – typ enum SynthesizerState, właściwość zwraca informacje o aktualnym stanie syntezatora, zwracane wartości to: SynthesizerState.Ready, SynthesizerState.Speaking lub SynthesizerState.Pause (tylko odczyt).
Listę zainstalowanych w systemie głosów możemy uzyskać wywołując metodę GetInstalledVoices():
var installedVoices = synth.GetInstalledVoices();
foreach (var voice in installedVoices)
{
string name = voice.VoiceInfo.Name;
VoiceGender gender = voice.VoiceInfo.Gender;
[...]
}
Aby zmienić głos wystarczy wywołać metodę SelectVoice, która jako parametr przyjmuje nazwę głosu np:
synth.SelectVoice("Microsoft Anna");
Istnieje również możliwość zmiany wyjścia, na które skierowany zostanie odtwarzany głos.
synth.SetOutputToDefaultAudioDevice();
Powyższa linia spowoduje, że po wywołaniu metody Speak, odtwarzany dźwięk będzie wysyłany na domyślne urządzenie dźwiękowe (zazwyczaj głośniki).
Aby zapisać dźwięk do pliku wave, należy najpierw ustawić wyjście następującą metodą:
synth.SetOutputToWaveFile(string path);
lub
synth.SetOutputToWaveFile(string path, SpeechAudioFormatInfo formatInfo);
a następnie wywołać metodę Speak. Jako parametry przyjmuje ona samą ścieżkę do wyjściowego pliku oraz ewentualnie informację o formacie audio (liczba sampli, bps, ilość kanałów itd.). Aby ustawić parametry o formacie audio, należy dołączyć przestrzeń nazw System.Speech.AudioFormat w sekcji using. Przykład użycia w załączonym kodzie źródłowym.
Dźwięk można również strumieniować, ustawiając wyjście metodami:
synth.SetOutputToAudioStream(Stream audioDestination, SpeechAudioFormatInfo formatInfo);
lub
synth.SetOutputToWaveStream(Stream audioDestination);
Syntezator daje nam dwie możliwości odtwarzania. Możemy odtwarzać mowę synchronicznie (metoda Speak) lub asynchronicznie (metoda SpeakAsync). Pierwszy sposób blokuje działanie programu, aż do zakończenia odtwarzania. Użytkownik nie ma dostępu do interfejsu, nie może zatrzymać odtwarzania. Lepszym rozwiązaniem jest wywołanie asynchroniczne. Dzięki temu dźwięk jest odtwarzany równolegle, co nie blokuje pracy aplikacji. Mamy również możliwość wstrzymania/wznowienia lub zatrzymania odtwarzania. Metodę wywołujemy następująco:
synth.SpeakAsync("tekst");
Do sterowania odtwarzaniem wykorzystamy następujące metody:
synth.Pause(); // wstrzymanie synth.Resume(); // wznowienie synth.SpeakAsyncCancelAll(); // zatrzymanie
Aktualny stan syntezatora otrzymamy odczytując jego właściwość State.
Klasa SpeechSynthesizer generuje kilka zdarzeń, które nasza aplikacja może subskrybować. Są to między innymi SpeakStarted, SpeakProgress oraz SpeakCompleted. Wywoływane odpowiednio po rozpoczęciu, w trakcie oraz po zakończeniu odtwarzania. Sybskrypcji możemy dokonać podpinając odpowiednie metody ich obsługi:
synth.SpeakStarted += SynthSpeakStarted;
synth.SpeakProgress += SynthSpeakProgress;
synth.SpeakCompleted += SynthSpeakCompleted;
private void SynthSpeakStarted(object sender, SpeakStartedEventArgs e) { ... }
private void SynthSpeakProgress(object sender, SpeakProgressEventArgs e) { ... }
private void SynthSpeakCompleted(object sender, SpeakCompletedEventArgs e) { ... }
Obsługując te zdarzenia mamy możliwość np. śledzenia bieżącej pozycji odtwarzanego tekstu, aktualny czas odtwarzania itd.
To tyle jeśli chodzi o podstawowe informacje dotyczące syntezatora mowy. Zapraszam do pobrania i analizy kodu przykładowej aplikacji. Polecam również eksperymenty z klasami Prompt oraz PromptBuilder, a także obsługę dodatkowych zdarzeń generowanych przez klasę SpeechSynthesizer. Zainteresowanym czytelnikom polecam zajrzeć na strony MSDN:
http://msdn.microsoft.com/en-us/library/system.speech.synthesis.prompt.aspx
http://msdn.microsoft.com/en-us/library/system.speech.synthesis.promptbuilder.aspx
http://msdn.microsoft.com/en-us/library/system.speech.synthesis.speechsynthesizer.bookmarkreached.aspx
http://msdn.microsoft.com/en-us/library/system.speech.synthesis.speechsynthesizer.phonemereached.aspx
http://msdn.microsoft.com/en-us/library/system.speech.synthesis.speechsynthesizer.visemereached.aspx
Jak zawsze przykładowy kod źródłowy oraz dodatkowo skompilowany gotowy do użycia plik wykonywalny. Do uruchomienia wymagane jest zainstalowane .NET Framework w wersji 4.0.
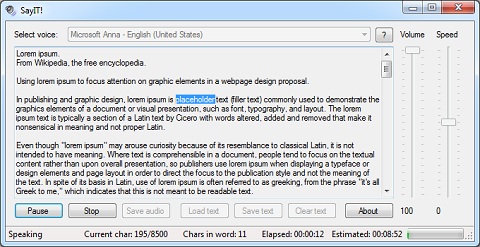
Funkcje oferowane przez przykładową aplikację:
- wybór głosu z listy (jeśli mamy zainstalowanych kilka) + info o wybranym głosie
- regulacja głośności oraz szybkości odtwarzania
- pauzowanie/wznawianie/zatrzymywanie odtwarzania lub eksportu
- aktualna pozycja odtwarzania, aktualny oraz przybliżony czas odtwarzania
- odczyt/zapis tekstu z plików tekstowych
- eksport do plików WAVe + konfiguracja
- odtwarzanie całości tekstu lub tylko zaznaczenia + podświetlanie aktualnie mówionego wyrazu
Do następnego wpisu!


“Wybór głosu z listy (jeśli mamy zainstalowanych kilka)” – jak mogę zainstalować polski “głos” dla frameworka 4.0 (nie mam 8.1 by mieć go zainstalowanego od razu)?